
Vuoi scoprire cos’è il file robots.txt e se potrebbe essere utile averne uno sul sito?
In questo articolo andremo a scoprire cos’è esattamente questo file, in quali situazioni ci può essere utile e come si fa a crearne uno.
Vedremo esempi specifici da seguire e scopriremo come evitare gli errori più comuni.
Iniziamo!
Indice

Cos’è il file robots.txt
Il file robots.txt, definito anche a volte semplicemente file robots, è un file di testo con delle istruzioni indirizzate ai motori di ricerca. Le regole utilizzate per dare queste istruzioni e incluse nel file vengono chiamate “protocollo di esclusione robot”.
Nello specifico queste istruzioni vengono lette dai crawler dei motori di ricerca, per esempio dai crawler di Google.
Apriamo una breve parentesi sul funzionamento dei motori di ricerca per rendere il concetto comprensibile a chiunque. Se vuoi approfondire, leggi il nostro post sul significato del termine SEO.
I crawler sono dei programmi che Google e altri motori di ricerca utilizzano per effettuare delle scansioni delle pagine dei siti web.
I motori di ricerca hanno l’obiettivo di raccogliere e classificare le informazioni in modo da portare a termine la loro funzione: fornire risultati pertinenti alle ricerche degli utenti.
Il processo che porta a questo risultato si articola in tre fasi:
- scansione (crawling): è la fase in cui le pagine vengono individuate;
- indicizzazione (indexing): in questa fase il contenuto delle pagine viene “letto” e la pagina viene inserita nell’indice. In questa guida dedicata all’indicizzazione puoi leggere in profondità il meccanismo di questa fase;
- posizionamento (ranking): i risultati vengono mostrati in ordine di pertinenza, il risultato di ricerca più valido verrà mostrato in prima posizione e via dicendo.
Nota che ci riferiamo per semplicità alle pagine, ma lo stesso processo avviene anche per immagini e per tutti gli altri tipi di contenuti.
È importante sapere che i crawler vengono indicati anche con altri termini:
- robot
- spider
- user agent.
Se vuoi sapere di più su questo argomento, sappi che abbiamo scritto un articolo dedicato ai crawler e al loro funzionamento.
In quali casi è utile usare il file robots.txt?
Il file robots.txt è usato per dare delle istruzioni ai crawler. Il caso più comune è quello in cui si indica al crawler di non effettuare la scansione di una o più pagine.
Uno dei motivi è quello di far sì che il crawler salti la scansione di pagine irrilevanti e scansioni, invece, solo quelle importanti.
Nel sito può capitare anche di avere pagine che non devono essere accessibili a tutti. Pensa per esempio a pagine destinate solo agli utenti registrati o anche risorse all’interno del sito che non vuoi che vengano sottoposte a scansione.
Un’altra ragione valida per sfruttare il file robots.txt riguarda il crawl budget o budget di scansione.
Considerando l’enorme quantità di siti web e contenuti, i crawler non possono sottoporre a scansione tutto. Per questo motivo può essere utile limitare la scansione di pagine irrilevanti, contenuti duplicati e così via per evitare che il pool di risorse destinato al nostro sito venga sprecato.
Ora che abbiamo visto a che scopo viene usato il file robots.txt, c’è una considerazione importante da fare sul suo utilizzo.
Bloccando la scansione di una pagina attraverso il file robots.txt non impediamo che la pagina venga mostrata nei risultati di ricerca. In questi casi, infatti, la pagina si potrà posizionare, l’unica differenza è che non verrà mostrata nessuna descrizione per quella pagina, come in questo esempio:
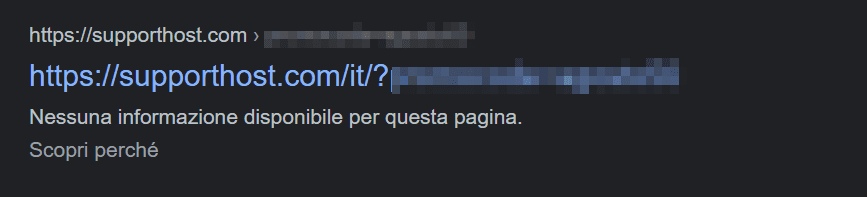
Se il tuo scopo è quello di evitare che una pagina web venga mostrata nei risultati di ricerca puoi usare il tag noindex.
Meglio usare il file robots.txt o il tag “noindex”?
Come forse avrai già capito il file robots.txt e il tag noindex hanno due utilizzi diversi.
Se non vuoi che una pagina venga mostrata nei risultati di ricerca, dovrai usare il tag noindex nella sezione “head” della pagina, in questo modo:
<meta name="robots" content="noindex">Il tag noindex serve proprio a comunicare a Google e altri motori di ricerca che quella pagina non deve essere “letta” e non deve essere mostrata nei risultati di ricerca.
Tieni sempre presente che questo non protegge completamente la pagina. Se non vuoi che nessuno abbia accesso a una risorsa specifica, il sistema più efficace è impostare una password tramite htaccess.
Nel caso in cui utilizzi il tag noindex nella pagina, devi assicurarti che quella stessa pagina non sia bloccata dal file robots.txt.
Infatti, se la pagina viene bloccata dal file robots.txt, il crawler non sarà in grado di leggere il tag noindex. Il risultato sarà che la pagina che non volevi venisse mostrata nelle ricerche, potrà invece continuare ad apparire!
File robots.txt: struttura e sintassi da usare
Un file robots.txt è un file con una struttura come questa:
User-agent: *
Disallow: /directory2/
Allow: /directory2/file.pdf
Sitemap: https://nomesito.com/sitemap.xmlEsempio di un file robots.txt di un sito WordPress:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-contents/
Allow: /wp-admin/admin-ajax.phpNella prima riga del file viene specificato l’user agent, vale a dire il crawler a cui sono indirizzate le istruzioni.
Le righe successive, disallow, allow e sitemap, sono chiamate direttive o istruzioni.
Se sono presenti, le righe che iniziano con “#” sono utilizzate per inserire dei commenti, come in questo esempio:
# Blocca l'accesso a Bing
User-agent: Bingbot
Disallow: /Vediamo cosa c’è da sapere su user agent e direttive.
Cos’è un user-agent
Come abbiamo anticipato prima, l’user agent è il robot (o crawler) che scansiona il sito.
Con il file robots.txt possiamo, infatti, scegliere di impartire delle istruzioni specifiche per ogni singolo crawler.
Tieni presente che nel file robots dovrai sempre inserire l’istruzione “user-agent:”.
Ogni motore di ricerca utilizza diversi crawler, uno dei più usati tra i robot di Google è Googlebot.
Nel file robots.txt possiamo indicare il crawler che vogliamo in questo modo:
User-agent: GooglebotIn questo caso le direttive che seguiranno saranno indirizzate solo a Googlebot, vale a dire uno dei crawler del colosso di Mountain View. Google ha diversi crawler:
- Googlebot-Image per Google Immagini
- Googlebot-News per Google News
- e così via.
Puoi consultare la lista di tutti i crawler di Google.
Altri user agent comuni sono elencati nella tabella qui di seguito.
Motore di ricerca | User-agent |
|---|---|
Google | Googlebot |
Google Immagini | Googlebot-Image |
Google News | Googlebot-News |
Bing | Bingbot |
Yahoo | Slurp |
Baidu | Baiduspider |
Baidu Immagini | Baiduspider-image |
Baidu News | Baiduspider-news |
Yandex | YandexBot |
DuckDuckGo | DuckDuckBot |
Ask | teoma |
AOL | aolbuild |
Nel nostro file robots, possiamo anche utilizzare il carattere jolly “*” per indicare che le istruzioni sono per tutti i crawler, così:
User-agent: *
Disallow: /In questo esempio qui sopra l’istruzione è rivolta a tutti i crawler (User-agent: *), e con la direttiva “Disallow: /” stiamo indicando di non sottoporre a scansione l’intero sito.
Cosa sono le direttive
Abbiamo visto che la riga che riporta l’user agent è sempre seguita da delle direttive. Ne esistono di tre tipi:
- disallow
- allow
- sitemap.
Tieni presente che c’è anche la direttiva crawl-delay. Visto che si tratta di un’istruzione non standard, non la inseriremo in questa parte della guida.
Controlla nelle domande frequenti in fondo all’articolo per vedere come impostare la frequenza della scansione tramite la Google Search Console e i Webmaster Tool di Bing.
Lo stesso vale per altre istruzioni che non rientrano nella documentazione di Google tra cui:
- nofollow
- noindex.
In particolare queste due direttive non sono più supportate da settembre 2019 come si apprende in questa nota di Google.
Passiamo ora a vedere alcuni esempi di file robots.txt che ci aiutano a capire come funzionano le direttive.
Disallow
La direttiva disallow viene usata per indicare al crawler di non effettuare la scansione. Può essere seguita da un percorso che corrisponde ad una pagina o una directory.
Un’alternativa è l’esempio che abbiamo visto prima, in cui la direttiva disallow ci permette di bloccare la scansione dell’intero sito, così:
User-agent: *
Disallow: /Tieni presente che la direttiva è case sensitive, vale a dire che distingue tra maiuscole e minuscole. Se, per esempio, scrivi “discount” non verranno esclusi i percorsi che iniziano per “Discount” e viceversa.
Per capire come funziona, vediamo alcune applicazioni specifiche.
Usare la direttiva disallow per una directory
User-agent: *
Disallow: /wp-admin/In questo caso stiamo indicando a tutti i crawler di non effettuare la scansione della directory “wp-admin”.
Per far sì che tutta la directory non venga sottoposta a scansione dobbiamo assicurarci di inserire “/” prima e dopo del nome della directory.
Questa istruzione include quindi tutti gli elementi all’interno della directory.
Usare la direttiva disallow per un percorso
User-agent: *
Disallow: /discountIn questo caso tutti i percorsi che iniziano con “/discount” verranno esclusi dalla scansione. Ecco alcuni esempi:
- /discount2022
- /discount/christmas.pdf
- /discount.html
Allow
La direttiva allow serve a specificare directory e pagine a cui il crawler può accedere.
Visto che di norma tutto il sito può essere scansionato, la direttiva allow ci permette di creare delle eccezioni in percorsi che abbiamo escluso con l’istruzione disallow.
Vediamo come funziona con un esempio di file robots.txt.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpIn questo caso stiamo bloccando l’accesso alla directory “wp-admin”, ma stiamo consentendo l’accesso al file “admin-ajax.php”.
Sitemap
Possiamo usare il file robots.txt anche per comunicare ai crawler la posizione della sitemap del sito.
In questo caso ci basta inserire l’istruzione in questo modo:
Sitemap: https://nomesito.com/sitemap.xmlAndiamo a sostituire l’indirizzo con l’URL completo della sitemap. Assicurati che l’URL sia corretto (www o non www, http o https).
Tieni presente che la sitemap è opzionale, puoi creare un file robots anche senza inserire il percorso della sitemap del sito.
Regole per creare un file robots.txt corretto
Quando andiamo a creare o modificare il file robots.txt dobbiamo assicurarci di scrivere tutte le istruzioni correttamente. Questo serve a evitare che le istruzioni non vengano lette o che le diverse direttive (allow e disallow) entrino in conflitto.
Ricorda sempre che pagine e directory non bloccate attraverso un’istruzione disallow possono essere sempre sottoposte a scansione.
Vediamo a cosa bisogna fare attenzione.
Ogni riga deve contenere una sola direttiva
La sintassi corretta di un file robots.txt sarà quindi questa:
User-agent:*
Disallow: / Un esempio di struttura errata sarebbe mettere su una sola riga più direttive, per esempio così:
User-agent:* Disallow: / Creare i gruppi all’interno del file robots.txt
Le direttive possono essere raggruppate all’interno del file robots.txt. Un gruppo sarà composto da questi elementi:
- la prima riga contiene “User-agent” e specifica il crawler a cui è rivolta;
- le righe successive contengono una o più direttive (disallow/allow).
I gruppi ci permettono di impartire istruzioni diverse a crawler diversi.
Vediamo con un esempio:
User-agent:*
Disallow: /discount
User-agent: Googlebot
Disallow:/promoLa prima parte delle istruzioni impedisce a tutti gli user agent di sottoporre a scansione i percorsi che iniziano per “/discount”. La seconda parte, invece, impedisce solo a Googlebot di effettuare la scansione dei percorsi che iniziano con “/promo”.
Ricorda sempre di fare attenzione a maiuscole e minuscole quando inserisci i percorsi.
Ecco un esempio dalla documentazione di Google che ci spiega nella pratica questa regola:

Usare i caratteri jolly
Quando impartiamo le direttive può essere utile sfruttare i caratteri jolly: “*” e “$”. Questi caratteri possono essere utilizzati per escludere dalla scansione alcuni gruppi specifici di URL.
- Il carattere jolly “*” ci serve a sostituire un numero variabile di caratteri (0 o più caratteri);
- il simbolo “$” serve a indicare la fine dell’URL.
Vediamo come fare con degli esempi.
Ipotizziamo di avere una serie di URL all’interno di un percorso e di volerli escludere dalla scansione. Gli URL che vogliamo escludere contengono la parola “libro”.
In questo caso possiamo usare questa istruzione:
User-agent: *
Disallow: /books/*libroAlcuni esempi di URL che verranno bloccati con questa direttiva sono i seguenti:
- https://nomedelsito.com/books/libro/
- https://nomedelsito.com/books/libro-1/
- https://nomedelsito.com/books/questolibro-1/
Mentre URL come questi qui di seguito non saranno bloccati:
- https://nomedelsito.com/libro-2/
- https://nomedelsito.com/categoriagenerica/libro-2/
Per bloccare tutte le risorse che contengono la parola “libro”, invece, possiamo fare così:
User-agent: *
Disallow: /*libroCon questo stesso metodo possiamo escludere dalla scansione gli URL che contengono un singolo carattere, per esempio un “?”. Un caso in cui istruzioni come questa possono essere utili è quello di escludere dalla scansione gli URL con un determinato parametro.
Ci basta fare come in questo esempio:
User-agent: *
Disallow: /*?Se, invece, volessimo escludere solo gli URL che terminano per “?” dovremo usare questa direttiva:
User-agent: *
Disallow: /*?$Possiamo anche impedire la scansione di uno specifico tipo di file, in questo modo:
User-agent: *
Disallow: /books/*.jpg$In questo caso stiamo escludendo tutti gli URL che terminano con l’estensione “.jpg” presenti a quel percorso.
Altre volte potremmo voler impedire la scansione delle pagine di un sito WordPress che utilizzano parametri di ricerca. Potremmo quindi usare una regola come questa:
User-agent: *
Disallow: *?s=*Precedenze tra le regole
Quando inseriamo una serie di direttive dobbiamo tenere presente che si possono generare dei conflitti tra una regola allow e una disallow.
Nel caso di due direttive che si contraddicono quale delle due verrà seguita?
La risposta dipende di caso in caso.
La regola generale nel caso di Google è questa: viene seguita la direttiva più specifica o quella meno restrittiva.
Per quanto riguarda Googlebot e i crawler di Google, possiamo fare riferimento agli esempi specifici riportati qui.

Leggi anche cos’è il web scraping e come limitarlo con le direttive del file robots.
Come creare un file robots.txt
Ora che abbiamo visto quali sono le regole da utilizzare per impartire le istruzioni nel file robots.txt, vediamo come fare a crearne uno.
Ci sono diversi sistemi:
- creare un file di testo manualmente;
- usare un generatore;
- usare Rank Math;
- usare Yoast SEO.
In pratica con i primi due metodi dovremo creare il file e caricarlo sul sito. Utilizzando un plugin WordPress come per esempio Yoast o Rank Math il file verrà generato in automatico dal plugin.
Vediamo passo passo come procedere.
Creare un file robots.txt manualmente
La creazione di un file robots è molto semplice. Ci basta creare file di testo con estensione .txt e inserire al suo interno le istruzioni per i crawler.
Puoi utilizzare un editor di testo come Blocco note (per Windows) o TextEdit (per Mac).
Non dimenticare che:
- il file deve avere questo nome esatto “robots.txt”;
- il file di testo deve avere la codifica UTF-8;
- devi creare un solo file per ogni sito.
Il nostro file robots.txt ad esempio potrebbe essere questo:
User-agent: *
Disallow: /wp-admin/In questo caso stiamo impedendo l’accesso alla cartella “wp-admin”.

Dopo aver creato il file dovremo caricarlo sul server.
Prima di vedere come fare, però, vediamo quale altra alternativa abbiamo per semplificare ulteriormente la creazione del file.
Usare un generatore di file robots.txt
Se vuoi la vita facile, puoi anche creare il tuo file robots direttamente con un generatore, come ad esempio questo.
Generatori come questo ti permettono di fare esattamente la stessa cosa, ma scegliendo le istruzioni in maniera semplificata.

Il vantaggio è che in questo modo eviti di fare errori mentre scrivi il file.
Creare il file robots con Yoast SEO
Se hai un sito WordPress e utilizzi un plugin per la SEO come Yoast SEO, puoi usare questo stesso strumento per modificare il file robots.txt del sito.
Per prima cosa puoi verificare se il file robots è presente aggiungendo all’URL del tuo dominio “/robots.txt”.
Dopodiché con Yoast SEO possiamo creare o modificare il file robots.txt del sito in maniera molto semplice.
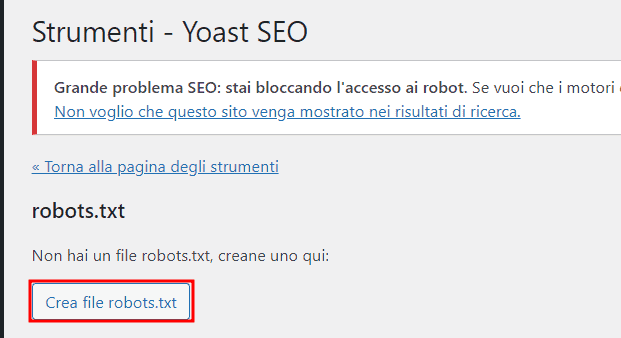
Clicchiamo su Yoast SEO > Strumenti e quindi facciamo click sul link Modifica file.

Nella sezione robots.txt vedremo un avviso che ci permette di creare un file robots.txt se ancora non ne esiste uno per il nostro sito web.
Potremo visualizzare il contenuto del file che viene popolato di default con queste direttive:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Quindi potremo effettuare le modifiche e aggiungere nuove direttive e cliccare sul pulsante Salva le modifiche al robots.txt per salvare.
Creare il file robots.txt con Rank Math SEO
Ci sono diversi plugin che ci permettono di creare con semplicità il file robots.txt, uno di questi è Rank Math SEO.
Clicchiamo su Rank Math dal menu laterale di WordPress e poi su Impostazioni generali. Da qui ci basta cliccare sulla voce Modifica robots.txt per visualizzare il contenuto del file robots.txt e modificarlo.
Tieni presente che il file non può essere modificato se risulta essere già presente nella root del sito, per esempio nel caso in cui è stato creato con uno degli altri metodi.
Il plugin Rank Math, infatti, non crea né modifica il file robots.txt presente sulla root, ma crea un file robots virtuale.
Se il file non è stato ancora creato, ci basta aggiungere le direttive come in questo esempio e poi salvare le modifiche.
Caricare il file robots.txt
A meno che tu non abbia utilizzato un plugin, dopo aver creato il file robots.txt devi caricarlo sul server.
Ricorda che puoi anche creare il file di testo direttamente sul server per esempio tramite il file manager di cPanel.

Se, invece, hai creato il file con un generatore o con un editor di testo sul tuo pc, dovrai caricarlo nella root. Per caricare un file sul server hai diverse alternative, per esempio:
- usare il file manager di cPanel o di un altro pannello hosting;
- usare un client FTP come FileZilla o Cyberduck.
Dovrai caricare il file robots.txt nella root del tuo sito web. Così facendo i crawler potranno trovare il file e leggere le istruzioni.
Se il sito per cui vuoi creare il file robots è:
https://nomedelsito.comIl file robots dovrà trovarsi alla radice (root) del sito e dovrà avere quindi questa posizione:
https://nomedelsito.com/robots.txtSe il tuo sito è accessibile su un sottodominio come:
https://blog.nomedelsito.comIl file dovrà essere posizionato nella directory del sottodominio, in questo modo:
https://blog.nomedelsito.com/robots.txtCome testare il file robots.txt
Dopo aver creato il file robots, è bene verificare che i crawler riescano a visualizzarlo.
Il file deve essere accessibile pubblicamente, vale a dire a tutti.
Il metodo più rapido è visitare l’indirizzo a cui deve essere presente il file e assicurarci che sia leggibile.
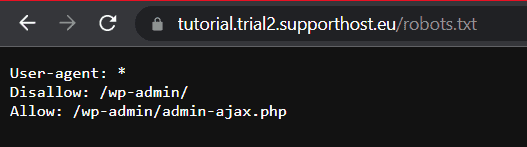
A questo punto possiamo anche verificare se la sintassi del file è corretta.
Per farlo, Google ci mette a disposizione il suo tester dei file robots.txt.
Aprendo il tester vedrai il contenuto del file e potrai testare i singoli URL attraverso il box in basso, come vedi qui sotto.

In questo modo potrai essere sicuro di non aver bloccato pagine importanti del tuo sito.
Ecco un esempio in cui lo strumento di Google ci segnala che la risorsa è bloccata e ci indica quale regola del file robots.txt ne impedisce la scansione.

Come controllo se ho commesso errori?
Usare il tester di Google ci può aiutare a capire l’impatto delle direttive e quali sono le pagine interessate.
Oltre a testare singolarmente i singoli URL, un altro valido strumento che può aiutarci a prevenire errori nel file robots.txt è la Search Console.
Nel rapporto Indice > Pagine, possiamo trovare una panoramica dell’indicizzazione delle pagine e dettagli su quelle che non sono inserite nell’indice.
In questo rapporto vedremo, se presenti, le risorse bloccate dal file robots.txt.
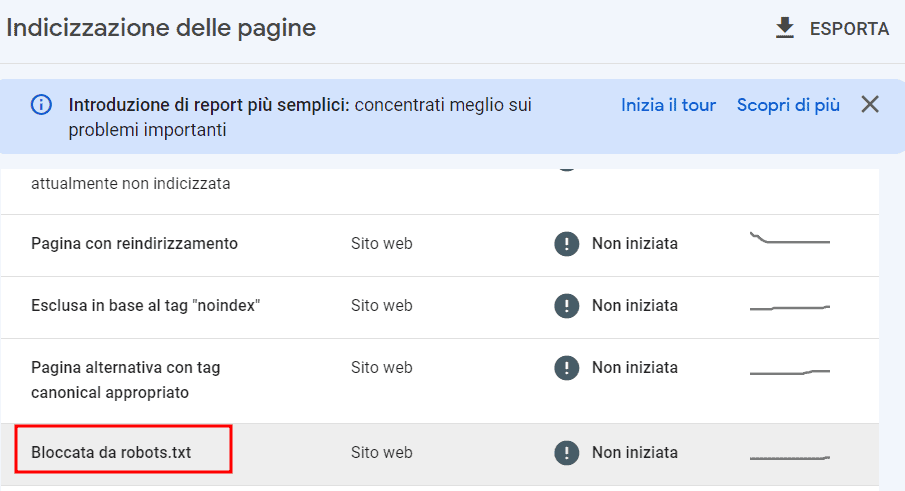
Da questa sezione possiamo visualizzare nel dettaglio gli URL bloccati dal file robots.txt e avere tutto l’elenco.
Se in questa lista risultano presenti pagine che non dovevano essere bloccate, possiamo utilizzare il tester che abbiamo visto prima, o semplicemente consultare il file robots.txt, in modo da capire quale regola sta impedendo l’accesso ai crawler e correggerla.
Domande frequenti sul file robots.txt
Come avrai capito arrivato a questo punto, questo file è utile per definire quali pagine devono essere sottoposte a scansione da parte dei motori di ricerca.
Ci sono però altri dubbi che potrebbero esserti rimasti.
Devo inviare il file robots.txt a Google dopo averlo creato?
No. Il file robots.txt deve essere creato e caricato sul sito.
Caricare il file sul tuo sito è sufficiente a far sì che i crawler possano trovarlo.
Dopo aver aggiornato il file robots.txt, devo fare qualcosa?
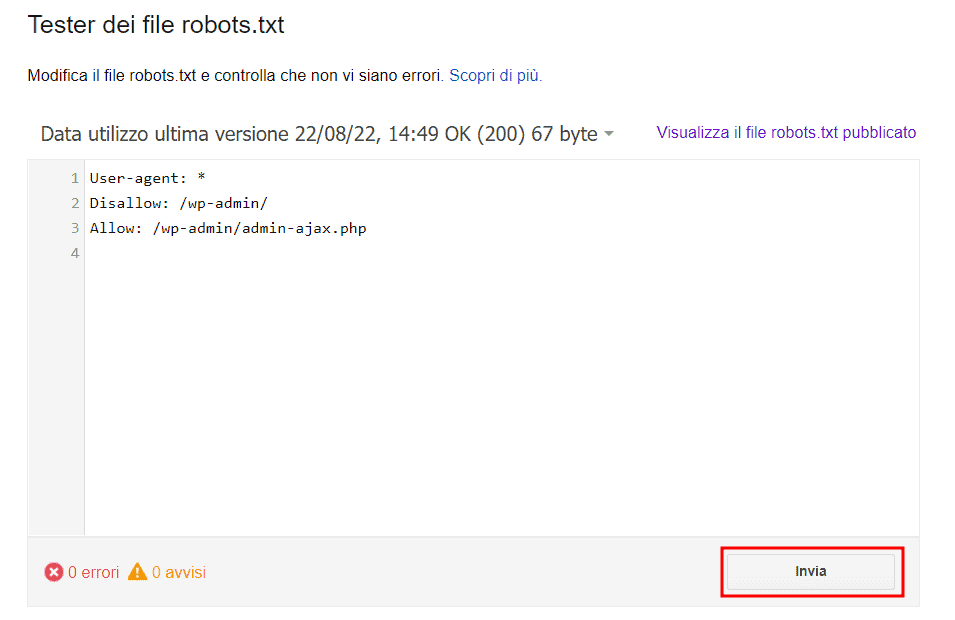
Secondo le linee guida di Google, se effettui delle modifiche al file robots e vuoi che siano aggiornate velocemente puoi utilizzare lo strumento Tester dei file robots.txt.
Tieni comunque presente che il file robots.txt viene memorizzato nella cache che viene aggiornata ogni 24 ore.
Dopo aver aperto lo strumento tester, clicca su Invia, in questo modo Google saprà che hai effettuato delle modifiche.
È necessario avere un file robots.txt su tutti i siti?
Ora che abbiamo visto l’utilità del file robots.txt è probabile che tu ti stia chiedendo se sia necessario crearne uno sul tuo sito.
La risposta è non necessariamente.
Nella pratica questo file ti può aiutare a impedire la scansione di alcune pagine. Se, però, non hai contenuti da bloccare e non hai altri motivi per bloccare la scansione di alcune sezioni del sito, allora non hai bisogno di un file robots.txt.
Non dimenticare che creare un file con un’istruzione errata può compromettere la scansione di tutto il tuo sito.
Veniamo perciò alla prossima domanda che riguarda proprio l’impatto sul posizionamento del sito.
Il file robots.txt può influire sulla SEO?
Quando eseguiamo un’analisi SEO del sito, uno dei controlli da fare è verificare il contenuto del file robots.txt.
Come abbiamo visto, errori nelle direttive possono impedire la scansione da parte dei crawler dei motori di ricerca e andare a interessare pagine importanti del sito.
Valgono sempre le considerazioni sul crawl budget fatte all’inizio di questo articolo.
Bisogna aggiungere anche un’altra cosa. I link che si trovano all’interno delle pagine bloccate tramite file robots non verranno scoperti dal crawler.
Immagina per esempio di aver inserito un link interno verso un post del tuo blog in una pagina bloccata tramite file robots. Se il link che rimanda al post del blog è presente in quell’unica pagina, i crawler non raggiungeranno mai il post.
Inoltre, come saprai, uno degli obiettivi dei link interni e dell’attività di link building è quello di passare link juice tra le pagine del sito.
In breve: con link juice si intende il valore che la pagina di origine del link trasmette alla pagina di destinazione.
Vediamo cosa succede con un esempio quando usi il file robots.txt per bloccare una pagina:
- Pagina A contiene il link a Pagina B;
- Pagina A è bloccata tramite robots.txt;
- Di consenguenza: Pagina B non riceve link juice da pagina A.
Per tutti questi motivi devi creare il file robots con cautela.
Posso modificare il crawl-delay (frequenza di scansione)?
L’istruzione crawl-delay serve a definire la frequenza di scansione. Nello specifico indica il numero di richieste che il crawler, per esempio Googlebot, può inviare.
Il crawl delay è espresso in numero di richieste al secondo.
Modificare la frequenza di scansione dei crawler di Google
Per modificare la frequenza di scansione devi agire tramite Search Console usando lo strumento Impostazioni della frequenza di scansione raggiungibile da qui.
Da queste impostazioni puoi limitare la frequenza di scansione.

Tieni presente che Google raccomanda di farlo solo nel caso in cui ci sia un valido motivo come un sovraccarico del server dovuto al bot di Google.
Modificare la frequenza di scansione dei crawler di Bing
Per modificare la frequenza di scansione con Bing puoi utilizzare lo strumento Crawl Control (Controllo ricerca per indicizzazione) dei Bing Webmaster Tools.
Utilizzando l’impostazione predefinita, le scansioni verranno ridotte quando il traffico sul sito è maggiore. Possiamo però anche impostare un intervallo personalizzato.

Conclusioni
Se sei arrivato fin qui nella lettura di questa guida avrai capito che il file robots.txt può essere estremamente utile. Abbiamo visto diversi modi per crearlo, come scrivere correttamente le direttive e quali aspetti considerare per non rischiare di commettere sbagli.
In conclusione abbiamo stilato una serie dei dubbi più frequenti sull’argomento, ma se hai altre domande o osservazioni da fare, ti invito a farci sapere con un commento.
Pronto a costruire il tuo sito WordPress?
Prova il nostro servizio gratuitamente per 14 giorni. Nessun impegno, nessuna carta di credito richiesta.


