
Vuoi sapere cos’è il web scraping, come funziona e a quale scopo può essere usato?
In questo articolo vedremo una panoramica di questo metodo che ci permette di ottenere grandi moli di dati in automatico, parleremo anche di risvolti legali ed etici ed esamineremo con quali metodi è possibile proteggere il proprio sito web.
Cominciamo proprio dal capire in cosa consiste lo scraping dei dati e come avviene.
Indice

Cos’è il web scraping
Il web scraping anche chiamato scraping di dati, content scraping o semplicemente scraping è una tecnica che permette di prelevare informazioni dalle pagine web.
Lo scopo di questa tecnica è infatti quello di identificare in automatico dati rilevanti all’interno delle pagine web, recuperarli e poi conservarli come dati strutturati.
L’obiettivo è avere i dati prelevati in un formato che permette di accedere facilmente alle informazioni e che permette di riutilizzarle, per esempio un file Excel.

Come funziona il web scraping
Il processo di web scraping varia in base allo strumento utilizzato, ma in generale si può suddividere in tre fasi:
- Lo strumento di web scraping viene usato per inviare una richiesta HTTP al server. Attraverso questa richiesta il tool sta chiedendo di accedere al sito allo stesso modo in cui il browser invia una richiesta quando apriamo una pagina web per visitarla.
- Dopo che il server risponde e consente allo strumento di accedere al sito, lo strumento può analizzare, per la precisione fare il parsing, delle informazioni nella pagina. In particolare lo strumento può accedere alla versione HTML o XML della pagina, visualizzarne la struttura e poter ricavare degli elementi specifici.
- La terza fase consiste nel prelevare questi dati per poi salvarli in diversi formati per esempio in un foglio di calcolo, in base alle impostazioni del programma che si sta utilizzando.
Strumenti per il web scraping
Il processo che abbiamo appena descritto è volutamente semplificato, ma ci serve a capire cosa c’è alla base del web scraping.
Quando parliamo di strumenti e di tecniche di scraping possiamo trovare diversi esempi.
Gli strumenti possono essere classificati in base al tipo:
- si può usare la programmazione per creare il proprio web scraper,
- si possono usare strumenti di web scraping già pronti da scaricare ed eseguire,
- oltre ai programmi, è possibile anche trovare estensioni per i browser.
Ecco degli esempi di strumenti di scraping gratuiti e premium.
Parsehub, ha un piano gratuito e piani con sottoscrizione mensile a partire da 189$ al mese.
Octoparse, disponibile con una prova gratuita che consente di eseguire un massimo di 10 operazioni, poi disponibile a pagamento con piani a partire da 52$ al mese (attualmente in offerta, costo regolare di 75$ al mese per il piano Standard).
Import.io, disponibile con un piano in prova gratuita per 14 giorni e poi con piani a pagamento a partire da 199$ al mese.
Tra le funzioni degli strumenti di web scraping ricordiamo:
- diverse modalità di scraping, sia in locale che in cloud;
- inserimento di liste di URL da analizzare;
- formati multipli di esportazione dei dati (tra cui CSV, XLS, JSON, TXT ed esportazione diretta in Fogli Google);
- possibilità di programmare l’esecuzione del programma per fare lo scraping a intervalli stabiliti;
- eseguire lo scraping anche di pagine che richiedono il login o la risoluzione di un codice captcha;
- cambiamento regolare degli IP per evitare di essere bloccati.
Creare il proprio web scraper
Chi sa come programmare può sfruttare una delle tante librerie di scraping per creare il proprio strumento personalizzato per la raccolta dei dati.
Uno dei linguaggi di programmazione più utilizzati per il web scraping è Python. Esistono infatti già numerose librerie che possono essere utili per creare il proprio script custom, tra cui Scrapy e Beatifulsoup.

Se si vuole creare uno strumento di web scraping con Python la prima cosa da fare è delineare l’idea:
- scegliere i siti da cui prelevare le informazioni;
- visualizzare la sorgente delle pagine che ci interessano per individuare gli elementi che vengono usati per le informazioni di interesse (si può anche usare lo strumento per sviluppatori del browser);
- abbiamo quindi le basi per creare il codice per il nostro programma;
- eseguire lo script per inviare la richiesta alla pagina;
- salvare i dati nel formato strutturato che ci è più comodo.
Come vedi alla base della creazione del proprio web scraper c’è l’analisi del sito che ci interessa. Questo è dovuto al fatto che ogni sito web è differente, per cui per recuperare le informazioni che ti interessano dovrai utilizzare metodi diversi.
Oltre a questo devi considerare che la struttura dei siti può cambiare nel tempo, per cui anche dopo aver creato uno strumento che funziona, potrebbe essere necessario fare delle modifiche per adattarlo ai cambiamenti dei siti.
Tipologie di scraping
Ci sono diverse tecniche di scraping.
Copia e incolla: la forma basilare di scraping dei dati è proprio la copia manuale dei contenuti di un sito. Si tratta però della tecnica meno efficiente perché non può essere automatizzata.
Analisi delle pagine HTML: il programma analizza la versione HTML della pagina per recuperare le informazioni contenute nei tag HTML.
Analisi dei documenti XML: si utilizzano altri tipi di parser come i DOM parser per recuperare le informazioni contenute nei documenti XML.
Espressioni regolari: si possono usare delle espressioni regolari per recuperare informazioni che corrispondono a un determinato pattern (pattern matching).
Recupero dei dati via API: quando accessibili le API possono essere utilizzate per prelevare le informazioni ricercate.
Le diverse tecniche possono anche essere combinate tra loro, ad esempio dopo aver usato una tecnica automatizzata e non essere riusciti a recuperare tutte le informazioni che volevamo, è possibile usare un sistema manuale per completare le informazioni. Lo stesso potrebbe succedere nel caso in cui alcuni dati siano inesatti e quindi da correggere.
Qual è la differenza tra crawling e scraping?
Un crawler o web crawler è un bot che visita i siti web per indicizzare i contenuti e seguire i collegamenti presenti all’interno di ogni pagina. I motori di ricerca come Google utilizzato i crawler per aggiungere al loro indice i contenuti delle pagine web. Leggi il nostro approfondimento sul significato della SEO per maggiori dettagli sull’indicizzazione e sul posizionamento dei contenuti sui motori di ricerca.
Uno scraper, invece, è uno strumento creato allo scopo di ricercare informazioni specifiche all’interno delle pagine, estrarle e poi raccogliere questi dati in maniera strutturata.
Per cosa viene usato il web scraping?
Gli utilizzi di questa tecnica sono molteplici, vediamo perciò alcuni esempi di web scraping.
Confronto dei prezzi: attraverso lo scraping dei dati si possono ottenere informazioni sui prezzi, sia per seguire le fluttuazioni del mercato che per confrontare i propri prezzi a quelli della concorrenza. Anche gli aggregatori di prezzi sono creati con lo scraping.

Aggregare i contenuti: dagli aggregatori di prezzi, fino a quelli di recensioni, di eventi, di notizie o di annunci (per esempio quelli immobiliari), il web scraping è usato per raccogliere in breve tempo una grande mole di dati.
Raccolta di dati a scopo di ricerca o analisi: spesso si cerca di prelevare molti dati in automatico per aggregarli all’interno di ricerche o per analisi di mercato.
Machine learning: le informazioni raccolte possono essere utilizzate come set di dati per addestrare le macchine.
Raccolta di contatti: tramite lo scraping dei dati si possono ottenere contatti come numeri di telefono e email. Tuttavia bisogna sottolineare che in base al GDPR queste informazioni non dovrebbero essere utilizzate senza aver ottenuto il consenso.

Il web scraping è legale?
Tecnicamente estrarre dati dai siti web con strumenti di web scraping non è illegale. Tuttavia bisogna comunque fare attenzione ad alcuni aspetti che rientrano più nella sfera dell’utilizzo etico che dell’infrazione della legge.
In primis i termini di servizio, se le condizioni del sito vietano espressamente l’estrazione e il riutilizzo dei dati, allora non sei autorizzato allo scraping.
Bisogna fare attenzione anche alle pagine protette da login, anche in questo caso c’è differenza rispetto alle informazioni accessibili pubblicamente.

Per non parlare poi anche del GDPR, se le informazioni contengono dati personali, non puoi riprodurle o utilizzarle senza il consenso specifico. In passato il Garante della Privacy si è espresso con un provvedimento proprio in un caso di scraping di dati.
Riguardo al content scraping per la riproduzione di parte dei contenuti (sia testi che immagini) bisogna anche fare riferimento ai termini del copyright: queste informazioni possono essere riprodotte su altri siti? Quali sono i termini specifici?
Molto dipende anche dall’uso che farai delle informazioni prelevate, per esempio non dovresti usarle a scopo commerciale se non hai avuto un’autorizzazione.
Per fare web scraping in maniera responsabile, quindi, occorre utilizzare il buon senso.
Bisogna rispettare i termini di servizio, il copyright e il GDPR.
È bene evitare di inondare i siti di richieste: tieni presente che le richieste inviate per fare scraping utilizzano le risorse del server, quindi un numero eccessivo di richieste può anche mandare in down un sito.
Oltre a limitare la frequenza delle richieste, l’ideale sarebbe anche programmare le richieste in modo da non eseguirle in concomitanza al picco di traffico che può avere il sito, per esempio limitandole a orari notturni.
Come proteggere il proprio sito dallo scraping
Come abbiamo detto, il web data scraping di fatto non è illegale, tuttavia il modo in cui viene eseguito e il modo in cui vengono utilizzate le informazioni prelevate non può essere previsto. Per evitare, quindi, che malintenzionati vogliano utilizzare i dati del tuo sito per scopi non autorizzati o per danneggiarti, ci sono diversi sistemi per cercare di arginare il fenomeno.
Vediamo alcuni spunti.
Imporre un limite al numero di richieste
Questo è forse uno dei metodi più importanti da mettere in pratica per ridurre il carico di lavoro sul server.
Come dicevamo, un numero eccessivo di richieste può dare problemi al sito perché può andare a saturare le risorse del server, un po’ come accade negli attacchi DDoS quando l’attaccante invia molte richieste per rendere il sito irraggiungibile.

Uno dei sistemi consiste nel limitare il numero di richieste in base all’IP, tuttavia tiene presente che questo limite può essere aggirato utilizzando indirizzi IP diversi.
Suggerimento pratico: se hai un piano con SupportHost come un hosting WordPress, puoi bloccare gli indirizzi IP (sia singoli che intervalli) da cPanel.
Utilizzare codici CAPTCHA
La presenza di un codice captcha che non può essere superato da un bot può impedire l’accesso ai sistemi di scraping, bisogna comunque sapere che ci sono strumenti in grado di superare questo tipo di protezione.

Identificare i visitatori
Ci sono metodi per capire se un visitatore è reale o è un bot, per esempio gli honeypot, delle trappole che possono essere utilizzate per identificare un tentativo di scraping, memorizzare l’IP da cui proviene e poi inserire l’IP in una blacklist o bloccarlo.
Aggiornare i tag HTML
Molti strumenti di scraping si basano su una formattazione regolare. Andando a introdurre dei cambiamenti nella struttura della pagina si può rendere più difficile l’estrazione dei dati.

Nascondere i dati
Ci sono sistemi che consentono di incorporare i contenuti testuali in elementi multimediali. Questa tecnica rende difficile ai programmi di scraping di reperire le informazioni, ma è comunque poco utilizzata.
Invece, per quanto riguarda le immagini, puoi adottare diverse tecniche per rendere più difficile la vita a chi cerca di prelevarle senza il tuo consenso. Se usi WordPress, ti potrebbe interessare la nostra guida su come prevenire il furto di immagini da un sito WordPress.
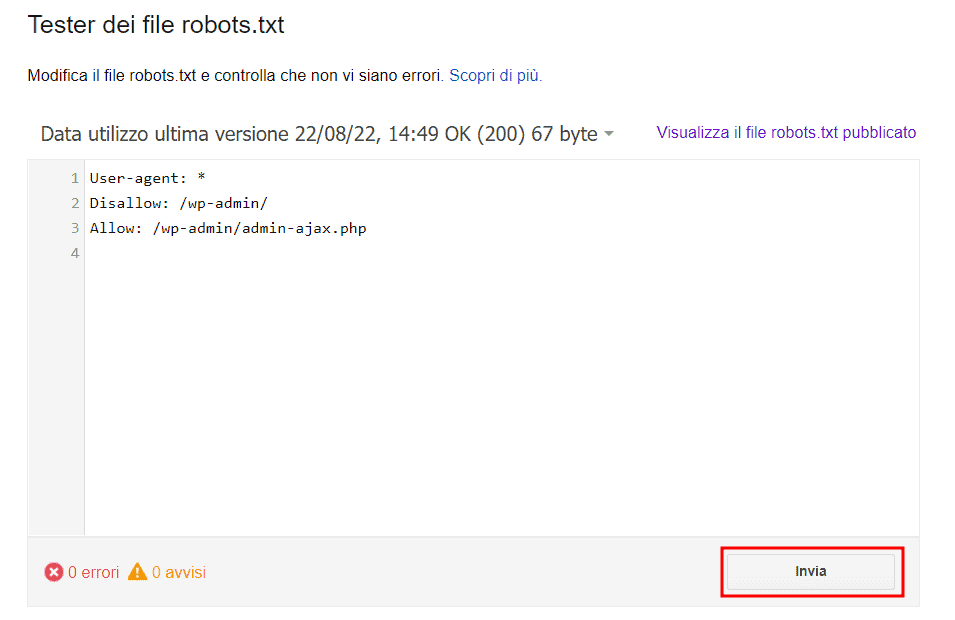
Stabilire delle regole nei termini e condizioni e creare un file robots.txt
Con un file robots.txt si può indicare quali link non devono essere accessibili, per esempio questo file viene seguito dai motori di ricerca e rispettato per escludere dall’indicizzazione alcune pagine.
Resta sempre inteso che uno strumento di web scraping con scopi malevoli potrebbe non rispettare le indicazioni di questo file o i divieti che hai stabilito nelle condizioni di utilizzo del tuo sito web.
Tieni comunque presente che gli strumenti di data scraping possono adottare numerose strategie per aggirare la maggior parte di queste limitazioni. Per esempio inviare richieste che passino come legittime grazie all’uso di indirizzi IP sempre diversi e ID di dispositivi generati in maniera casuale, oppure riuscendo a oltrepassare i codici Captcha.
Non c’è quindi un sistema per bloccare completamente i tentativi di scraping. Servizi di gestione dei bot come quello offerto da Cloudflare (bot management) possono ridurre gli accessi e le attività indesiderate sul sito riconoscendo i bot malevoli da quelli “buoni” e dal traffico reale.
Conclusioni
Adesso hai una panoramica completa sull’argomento web scraping, conosci le tecniche principali che possono essere usate per estrapolare i dati dai siti internet e alcuni degli strumenti di scraping più conosciuti.
Ovviamente non abbiamo tralasciato nemmeno l’altra faccia della medaglia: visto che lo scraping non viene sempre usato con buone intenzioni, ci sono diversi sistemi che ci vengono in aiuto per proteggere i nostri siti web.
In questo caso oltre ad eventuali strumenti esterni, è consigliabile avere un piano di hosting che ti permetta di limitare l’accesso a determinati indirizzi IP e monitorare l’utilizzo delle risorse. Se vuoi avere accesso a questi e altri strumenti per la gestione del tuo sito, attiva un piano hosting gratuito su SupportHost, potrai provare il servizio senza impegno per capire se fa al caso tuo.
Pronto a costruire il tuo sito WordPress?
Prova il nostro servizio gratuitamente per 14 giorni. Nessun impegno, nessuna carta di credito richiesta.


